Cloud Tank
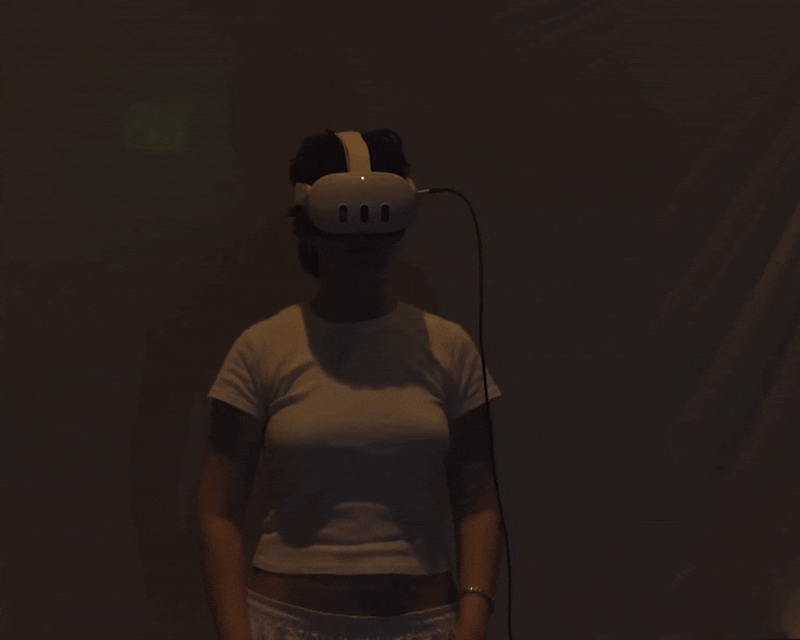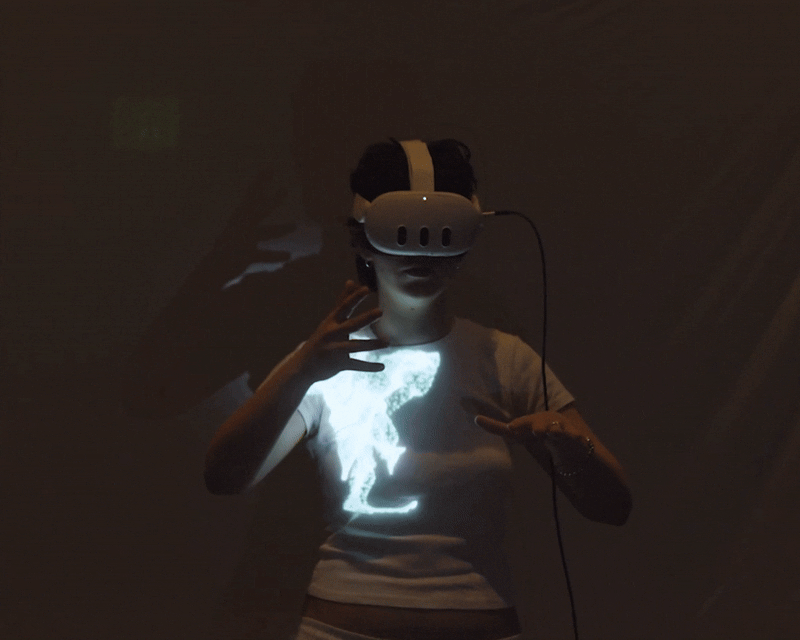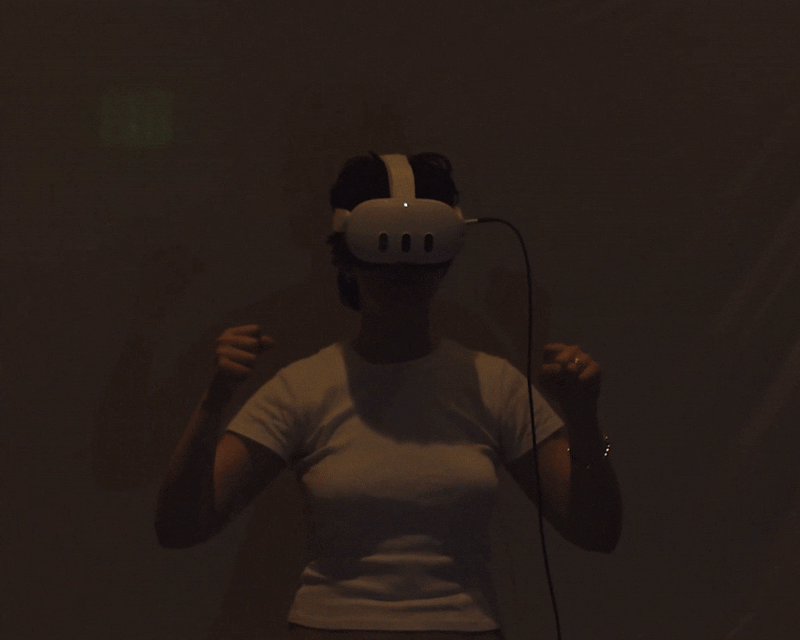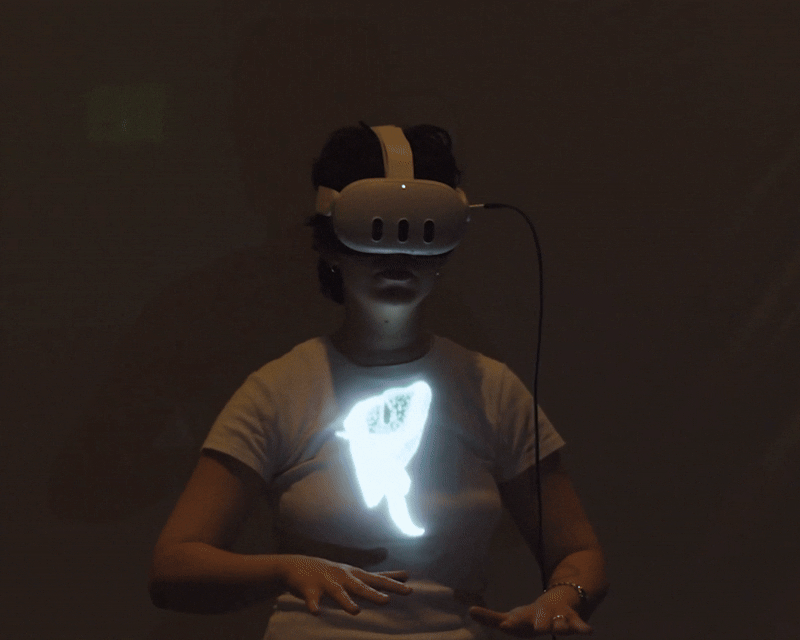
Piece 1: Hand gesture recognition for visuals

Piece 2: Prefab initiation and motion sliders
Overview
Cloud Tank is a virtual reality instrument for live performance. The performer wears a Meta Quest 3 headset and controls spatialized audio and reactive visuals entirely through hand movement and pose recognition — no controllers, no laptop, no desk. The audio and visuals stream in real time to a projector, so the audience watches the performer's body move to make the work, seeing the output projected behind them. They don't wear a headset. The result collapses the usual separation between the artist and the artwork: movement, sound, and image become one performance.
Video
Piece 2: Build
The video shows the audience view: the performer moving and the audiovisual output live-streaming to the projector. On the top left, performer's view from the headset is shown.
Technical Overview
Cloud Tank is built in Unity 6 for the Meta Quest 3 and organized around six concurrent subsystems: a content layer, a temporal layer, an audio analysis layer, an embodied input layer, a gesture-to-parameter mapping layer, and a streaming output layer.
Input comes from the hands and body. The Meta XR framework provides continuous joint data — wrist position, finger curl, orientation — and recognizes discrete poses that trigger audio and visual events.
Audio analysis runs every frame. Each of the four audio buses (Music, Percussion, Atmos, and FX) is continuously read for amplitude, frequency-band energy, and onset events. These values feed directly into the visual layer, so the image reacts to the sound in real time rather than on a fixed timer.
The visual output is a second camera positioned in the virtual space, rendering only what the audience sees, not the performer's interface, and broadcasting over WebRTC at 2560×1440 and 60 frames per second. The performer sees the full workspace; the audience sees only the composition.
Responsiveness shaped every architectural decision. Per-bus analysis runs every frame rather than at audio rate. Envelope smoothing uses asymmetric attack and release so visuals snap up on transients. Gesture-driven volume changes interpolate rather than jump. The goal throughout was that performing feels continuous.